The routine, traditional interpretation of a derivative is as a slope of the tangent line. This is great for a function of a single variable, but if you have a multivariate function 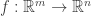 , how can you talk about slopes? One approach is to make a conceptual leap: a derivative is a linear approximation to your function; the tangent line itself is the derivative, rather than the slope of the tangent line. This is called the Fréchet derivative.
, how can you talk about slopes? One approach is to make a conceptual leap: a derivative is a linear approximation to your function; the tangent line itself is the derivative, rather than the slope of the tangent line. This is called the Fréchet derivative.
Suppose you have a multivariate function . At some point in the domain 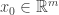 , we want to say that if you make a small change
, we want to say that if you make a small change 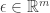 around
around  , the change in
, the change in  is approximately a linear function in
is approximately a linear function in  :
:
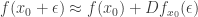
Here  is our notation for the derivative function (which is linear, and can be represented as a matrix applied to ).
is our notation for the derivative function (which is linear, and can be represented as a matrix applied to ).  could depend highly on ; after all, will probably have different slopes at different points. More formally, we want a function such that
could depend highly on ; after all, will probably have different slopes at different points. More formally, we want a function such that

where  is a function that “is tiny compared to ” e.g. every entry of the vector is the square of the largest entry of .
is a function that “is tiny compared to ” e.g. every entry of the vector is the square of the largest entry of .
Computing Fréchet Derivatives is Incredibly Elegant
To compute  , just plug in
, just plug in 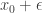 to , collect all the terms that are linear in , and drop all the terms that “get small as
to , collect all the terms that are linear in , and drop all the terms that “get small as  “. In practice, this means we drop all “higher-order terms” in which we multiply two coordinates of . The best way to illustrate is with examples.
“. In practice, this means we drop all “higher-order terms” in which we multiply two coordinates of . The best way to illustrate is with examples.
Example 1: f(x) = x^Tx
If we change  a little, how does
a little, how does 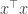 change? Here
change? Here  is
is 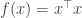 .
.


The part linear in here is  , and
, and 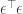 is tiny compared to . So
is tiny compared to . So
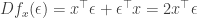

If we want to see where is minimized, the critical points are found by finding where the function 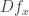 is 0; that is, where we can’t move a little bit to go up or down. In this case,
is 0; that is, where we can’t move a little bit to go up or down. In this case,

Example 2: Derivative of the Matrix Inverse
Let’s look at a function of a matrix,


As we change  by a matrix
by a matrix  with small entries (in particular, small enough to ensure
with small entries (in particular, small enough to ensure  is still invertible), how does
is still invertible), how does  change from
change from 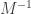 ? Just thinking about dimensions, the answer to that question should be by adding a small matrix to .
? Just thinking about dimensions, the answer to that question should be by adding a small matrix to .

The hard part is massaging to look like plus a linear function of . To start,

The matrix  can be inverted using the Neumann series, which is just a fancy name for the geometric series summation formula
can be inverted using the Neumann series, which is just a fancy name for the geometric series summation formula
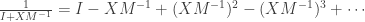
Note that the series converges for small enough because  has all eigenvalues less than 1.
has all eigenvalues less than 1.
Because is small, 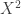 is negligibly tiny. For our linear approximation, we can drop the terms that are too tiny to be noticed by the linear approximation, which is all but the first two terms of this series.
is negligibly tiny. For our linear approximation, we can drop the terms that are too tiny to be noticed by the linear approximation, which is all but the first two terms of this series.
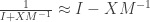
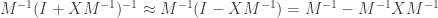
Remembering , altogether we just computed

Noting that this second term is linear in , we have the derivative

As a remark: whenever we wrote 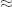 , we could have written
, we could have written 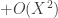 to be a little more formal about carrying the higher-order terms through the computation.
to be a little more formal about carrying the higher-order terms through the computation.
Example 3: Derivative of the Log of the Determinant
Now let’s do another example of a matrix function, the log of the determinant

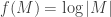
This function arises frequently in machine learning and statistics when computing log likelihoods.
Change by a matrix which has small entries

Now let’s look at  . Each of the entries of
. Each of the entries of  is “small”, though they’re essentially the same size as elements of (just differing by a few constants depending on ). The determinant of a matrix
is “small”, though they’re essentially the same size as elements of (just differing by a few constants depending on ). The determinant of a matrix  is a sum over all permutations
is a sum over all permutations

When performing this sum for 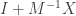 , if a product contains two off-diagonal terms, those will be two “small” terms from multiplied together, and multiplying two small terms makes a negligible term that we drop. So we only need to sum up
, if a product contains two off-diagonal terms, those will be two “small” terms from multiplied together, and multiplying two small terms makes a negligible term that we drop. So we only need to sum up  that include at least all but 1 diagonal elements. The only permutation that does this is the identity permutation.
that include at least all but 1 diagonal elements. The only permutation that does this is the identity permutation.

Same trick: this sum has  terms, but any term that multiples an
terms, but any term that multiples an 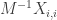 with a
with a 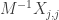 is negligibly small. To get a term with at most one of the , either we (1) take 1 from every factor, or (2) take 1 from all but one factor
is negligibly small. To get a term with at most one of the , either we (1) take 1 from every factor, or (2) take 1 from all but one factor


This is our linear approximation 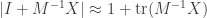 . To incorporate the log, note that we’re taking the log of something that is pretty much 1. The normal derivative of log at 1 is 1, and in our Fréchet derivative formulation
. To incorporate the log, note that we’re taking the log of something that is pretty much 1. The normal derivative of log at 1 is 1, and in our Fréchet derivative formulation

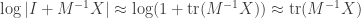
And so the derivative is  .
.
As a remark: incorporating log illustrates the composability of Fréchet derivatives. This makes sense when spoken aloud: if we have a linear approximation 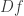 to and a linear approximation
to and a linear approximation 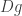 to
to  , a linear approximation of
, a linear approximation of 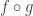 is
is 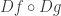 .
.
Other Viewpoints
Actually,  where
where  is the Jacobian matrix of partial derivatives
is the Jacobian matrix of partial derivatives  . But it’s often easier to not compute the Jacobian entirely, and keep in an “implicit” form like in Example 2.
. But it’s often easier to not compute the Jacobian entirely, and keep in an “implicit” form like in Example 2.
See another description of Frechet derivatives in statistics.

Nice!
– HTS
LikeLike